Science Says…
MASKS OFF

Science Says…
MASKS OFF
Visible progress on the 7pm project has slowed. Not for lack of interest, more because I am weighing different options to take moving forward. Right now, I do not feel that processing all those old days of cheering is impactful enough. The initial concept works for me, plus I was learning a ton on the fly in doing it. Right now, it feels more like following formula and just trying to achieve more volume of work, as opposed to quality of work.
Other things on my mind are that there was no cheering on either Christmas Eve, Christmas Day, New Years Eve, or New Years Day. Folks like Stephanie Zessos, a FEMA Emergency Management Specialist, have told me that this is the way it is with all disasters, there comes a time where the outpouring of good will fades. Here in New York, we are finding ourselves still heavily in the throws of the pandemic. So, I am of the opinion, at this moment, that I should be looking for a way to capture things that are more current. I am still not sure that I know what that is, but I am going to try some stuff.
At this point, I would like to thank all my neighbors and family and friends for being just who they are: caring; resourceful; adaptable; generous folks. Celebrating the holidays in a new way turned out to be great fun. I am very thankful for good health and good fortune. I also miss a lot of people who died during the pandemic. Ironically, almost none were COVID related. I want to make sure that folks who died from causes other than COVID are remembered with the same reverence – and to send a message of empathy to their families who were not able to mourn as they would have preferred, who have been forgotten by the media. You are all in my thoughts.
On the upside, I have continued to learn and do new things. As I am now working, teaching and making everything at home, I have been spending time getting my work space (all 40sq ft. of it) into a good shape. It started with building out a new desk, which then led me into a whole carpentry rabbit hole (rabbet grove?). I upgraded some of my tools and now have a few new projects in process, including building storage/organization for the studio (the 8 sq ft next to my desk which is part of the whole 40 sq feet. I will be posting bits an pieces of the process, resources, and revelations encountered along the way.
Another new thing I started learning about and doing is fermenting/brining vegetables. Last November, before COVID and before it was cool, I started baking Sourdough Bread. That has been super satisfying. I love being involved in a process that is actually alive. Following on, this November I started making Pickles and Sauerkraut. It is truly astonishing to learn that with only fresh vegetables, water, salt and an appropriate vessel, you can make fantastic tasting things – from hot pepper sauce to spicy pickled carrots – and the classics half-sour dill pickles and sauerkraut. Yesterday I took a leap forward and started a batch of pickled beets and eggs.
So, still really busy here. But not doing what I thought I would be doing. And that is all right with me.
Oh yeah – I have been reading a lot of books about musicians – many are autobiographies – many are disappointing. Some have been incredibly inspiring. I’ll do another post on that, perhaps.
To everyone in the world – Let’s lead with Love in 2021
Have a healthy, happy, peaceful, and prosperous year.
Nick
November 26, 2005, Thanksgiving here in the USA. My favorite holiday, because of simple goal of the day. No gifts, only re-affirming the bonds of family and friendship and as a whole. No guilt, only shared expression of the bounty of things we have to be thankful for – represented by a bounteous feast. Thanksgiving is all about putting aside the petty, and looking into your heart and head and realizing that no one makes it alone, everyone has at least one person to be thankful for.
The notion that the thanks we offer others connects our gathering, spiritually perhaps, to scores and scores of other gatherings. All of those gatherings’ expressions of thanks reach hundreds and hundreds of other gatherings, etc. An ephemeral network of connections -based on thanks and gratitude – lives for a short while on the ethereal plane. And it’s not just for Americans. There is always thanks given to people and groups in far off places. How do we nurture this phenomenon to be more inclusive of the whole earth? How do we make the gratitude network permanent? How can we make the warm embrace that this symbolizes more tangible? How can we make it more accessible?
I started this project as an open ended exploration of gratitude and thanks, as represented by the phenomenon in which people would open their windows at 7pm and clap and cheer in thanks for all those who were keeping us alive, those on the frontlines and those doing essential jobs. I am fairly certain that many of the gatherings, though much smaller that usual, officered thanks to those workers, but they probably expressed it at the table and not out the window.
That a phenomenon designed to celebrate those who are working to keep the rest of us going did not manifest on a day dedicated offering Thanks and Gratitude – in a time when the virus continues to spike (so they are still at risk) and to top it off, are working on a holiday when they should be with loved ones. Seemed like a moment for a massive outpouring. It was not to be.
This was a real wake-up call for me. I have been toiling, in fits and starts on this project since last April. Last month or slow I have not been doing and posting much work. There are always excuses. My response to the lack of cheering is that I am going to begin spreading the word of this project – unfinished as it is. Why would I hold back the real expressions of gratitude made by many, anonymously, with nothing but thanks and good wishes to fellow humans.
Anyone who takes the time to explore will have my gratitude and anyone who explores the project and shares it with a friend (building that ephemeral network of connections -based on thanks and gratitude) will have my gratitude and thanks. For those who would like to participate, in any way… welll… you’ll get MORE gratitude and thanks ;^ ).
Please understand that this is still being developed. There are rough edges and it may seem a little confusing. Fear not. Here are some initial links to help get you oriented. From there, you are free to explore.
Start Here:
7pm The Clappy Hour Project | katsivelos.com
These are good example of what a content page should have:
Friday May 8th @ 7pm | katsivelos.com
Saturday May 9th @ 7pm | katsivelos.com
Sunday May 10th @ 7pm | katsivelos.com
(this is actually where I paused the audio work, the May 20 & 21 pieces were the first ones I did.)
This next one doesn’t have any processed recording, but it lays out a vision of how this project could become some sort of digital manifestation of the that network that envelops the ethereal plane.
7pm Project Update – Nov 10, 2020 | katsivelos.com
Thanks for reading this far, go ahead take the plunge!
I would be very grateful if you would leave a comment or two
All the best to you and yours and thanks for all you do
Nick Katsivelos
November 27, 2020
It’s been a month since I processed the May 10th recording and put together the post. Why slow down? What else has been going on?
Well, it’s actually been a pretty busy few weeks for me and the family, and the neighborhood, and the city and the country and the world. In response to all of this activity, I decided to sit back a while and try to process my thoughts instead of audio files.
News Break:
On November 7th, clapping broke out at random moments and at 7pm when the election returns had provided enough data for media outlets to announce the winner of the presidential election. At an random moment that day, someone would open their window and cheer and clap. Sometimes it was greeted with a crowing chorus others were simply lone voices. I think this mode of expression is going to be with us for a while
First order of business on the project is to simply document one of the new goals of this project. 7pm Somewhere is what I am calling the platform evolution of the project. In short what I have already been doing is:
7pm Somewhere would take the very static structure I have:
Day’s recording at my location + Unique Processing Algorithm for that Day’s recording (and thus my location) + Some contextual info about My Location on that day
Let’s make this a little more math-ish
R = Recording (1 per day at fixed location at 7pm)
D = Day (20200429 – 20200709)
L = Location (fixed)
P = Processing (Unique Per Day, may have more than one per day)
C = Context (Unique per day, news and data from Location and other information about the days recording process and insights)
PD(RDL) + CDL = One Perspective on One Location on One Day
But this is a global phenomenon – I thought WWJBD? Well, the realization is that It’s always 7pm Somewhere (with a nod to Jimmy Buffet and Alan Jackson – let the conjuring begin) What we all want is to get together and party – folks from all over the world – we all have a common experiences – all of us! I there is a prime opportunity for people to come together, I can’t think of a better one than this.
7pm Somewhere goal is to provide a platform for people all around the world to bring their:
The 7pm Somewhere Platform would allow folks to mix and match recordings and processed to create new soundscapes. This would begin the creation of a graph that would connect locations (recording by location and day, processing by location and day, context by location and day). That is, someone could upload a recording from Barcelona (41.405825 North, 2.165260 East ) from July 12th, select my processing algorithm from May 5th, create a new soundscape that connects our two locations and those two dates, plus the date the processing algorithm was originally used. That person could also upload contextual information regarding their date and location. This would allow for the remixing and connecting of experiences. The platform would provide a centralized location for listening, creating, sharing, studying the 7pm phenomenon.
Please let me know if you think this is interesting and would like to participate. I do not ascribe to the build it and they will come approach. Just leave a comment. Now it’s time for me to get back to the tasks at hand. New soundscapes should be out soon.

An exploration of community and the expression of thanks given nightly to Frontline and Essential workers during the COVID-19 pandemic.

This is a whole new way of of individually or collaboratively creating new and sharing new expressions of knowledge, while insuring that each contributors lived experience, world view, and personal context is baked right in.
More to come in October.
Good Things – I just rebuild my Aeron Chair. I got it when the digital agency I was with went belly up in the dot bomb. $300 cash. A bargain. It has lasted me 20 years at home, but with all the wear and tear it was getting this year, it needed a little TLC. So, I got these parts my amazon shopping list and I followed the directions, used a little PB Blaster to help with the rubber mallet part. Chair is good as new and rolls a heck of a lot quieter on the wood floors.
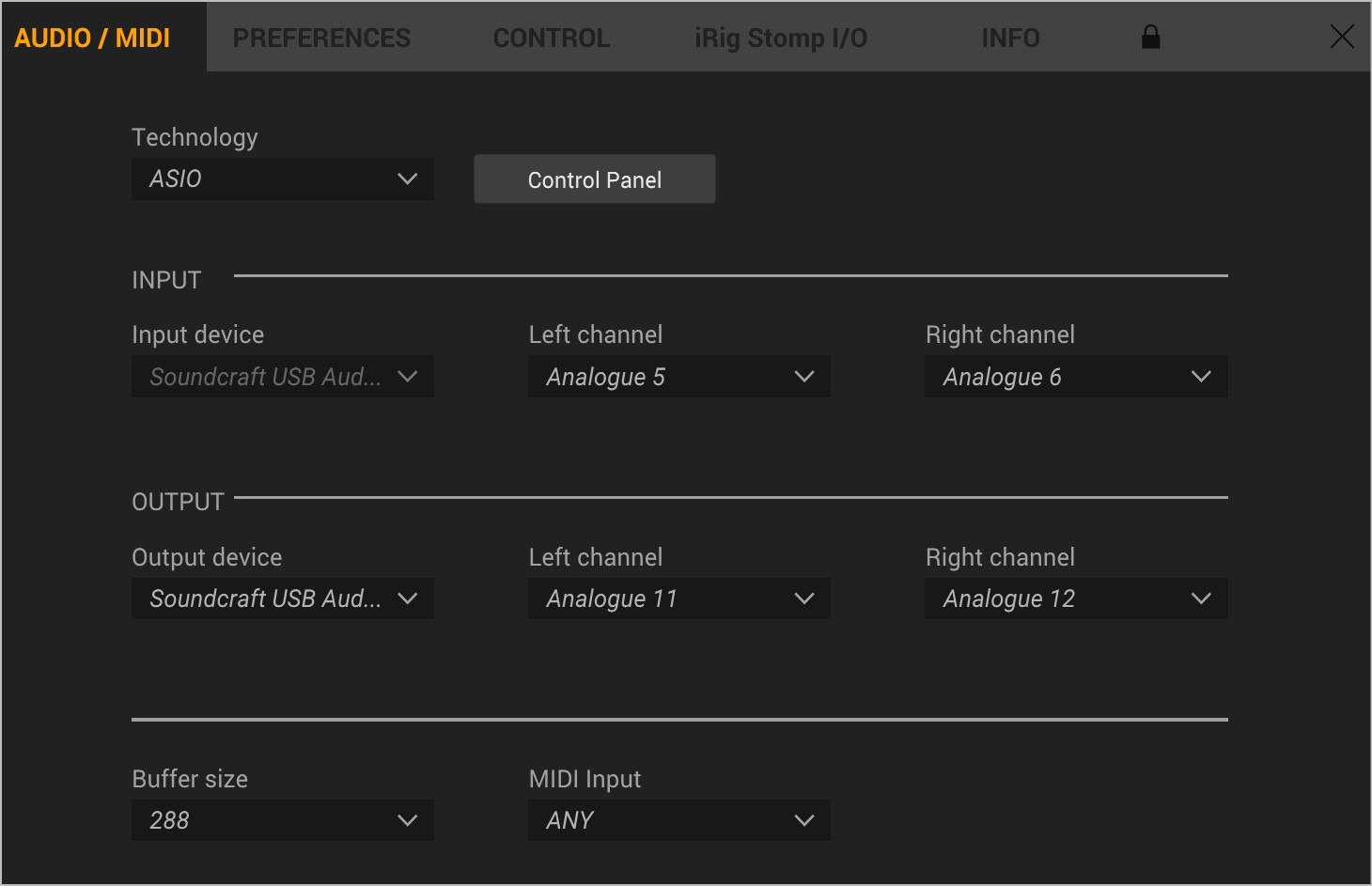
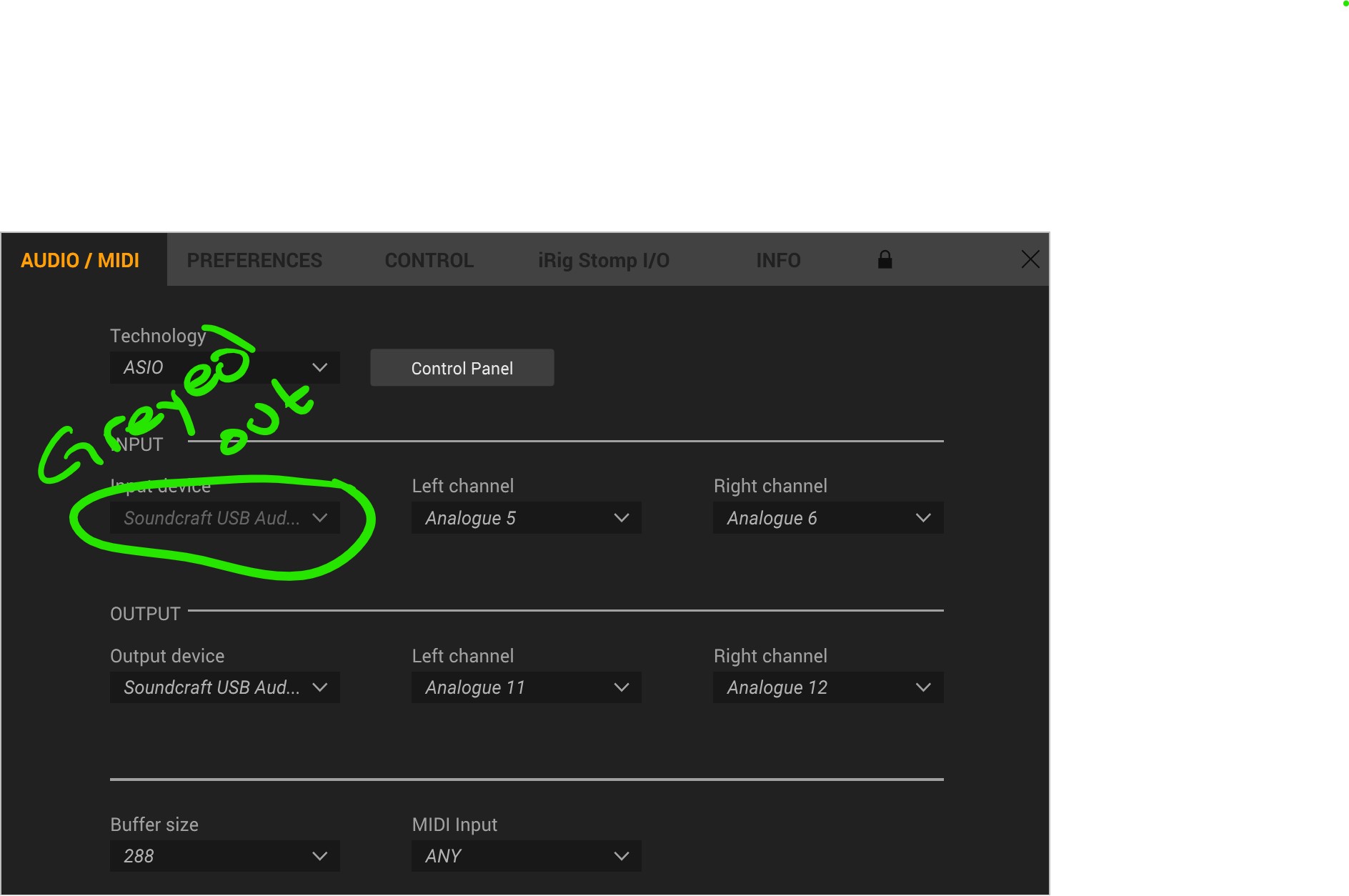
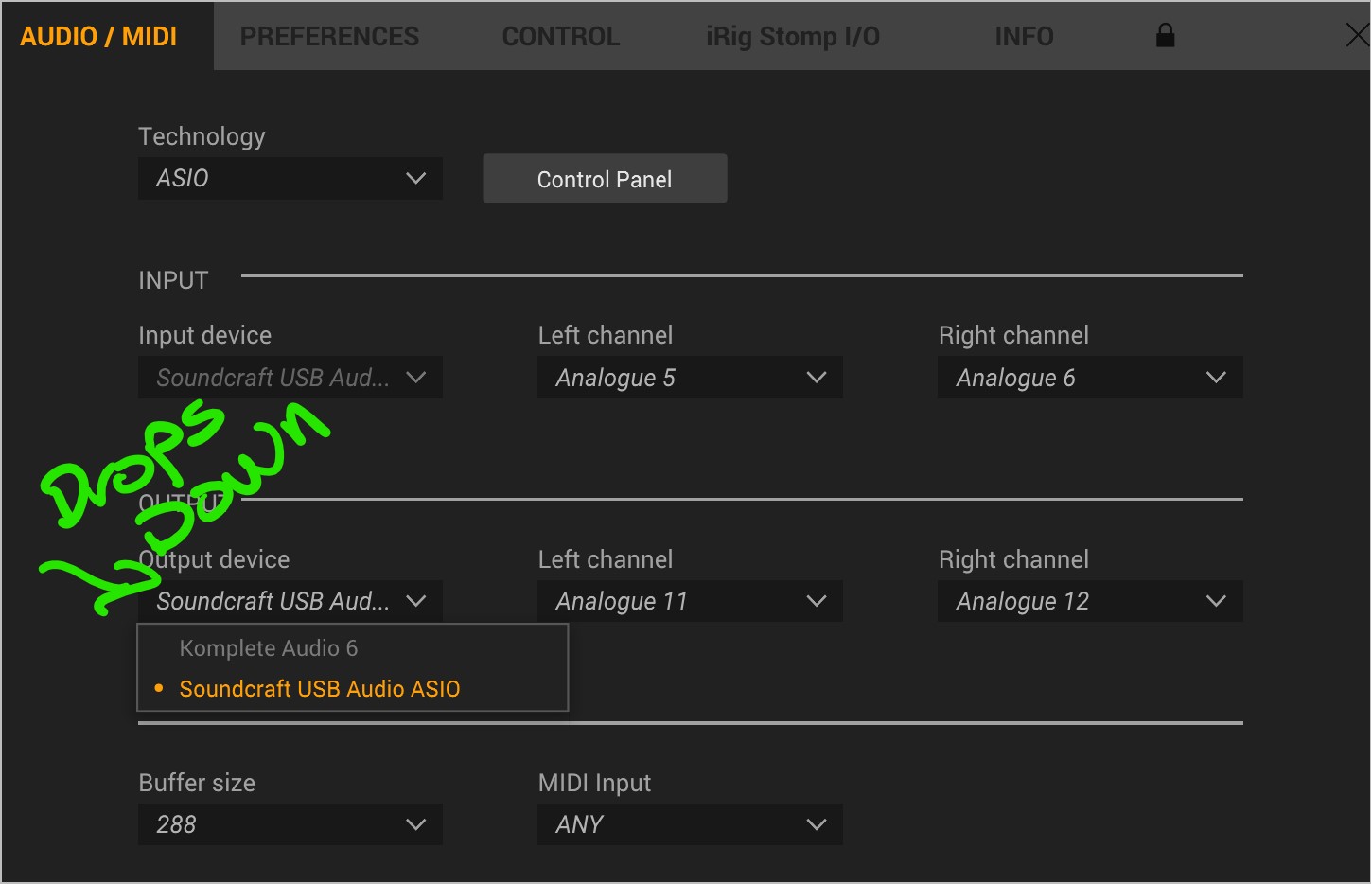
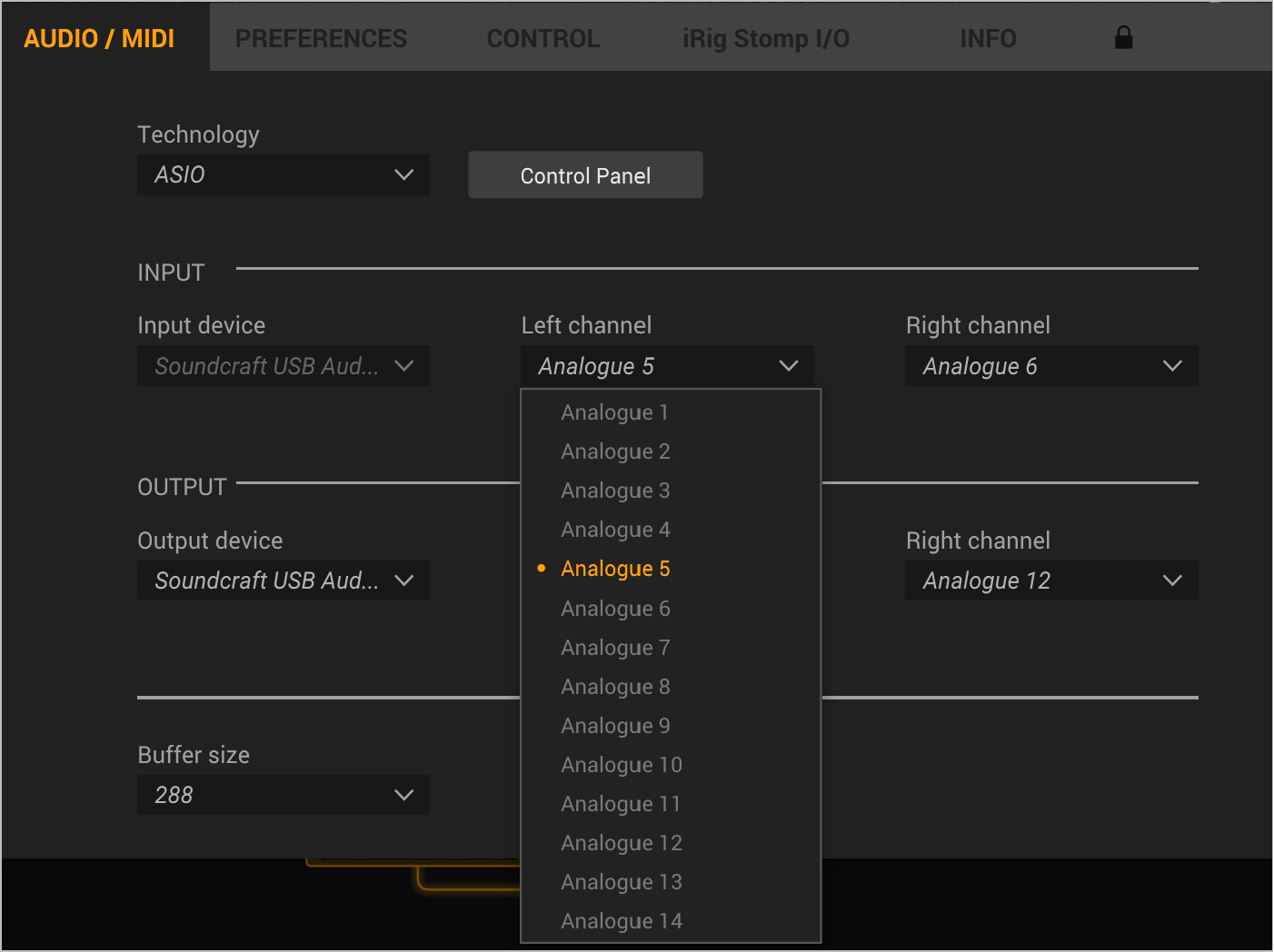
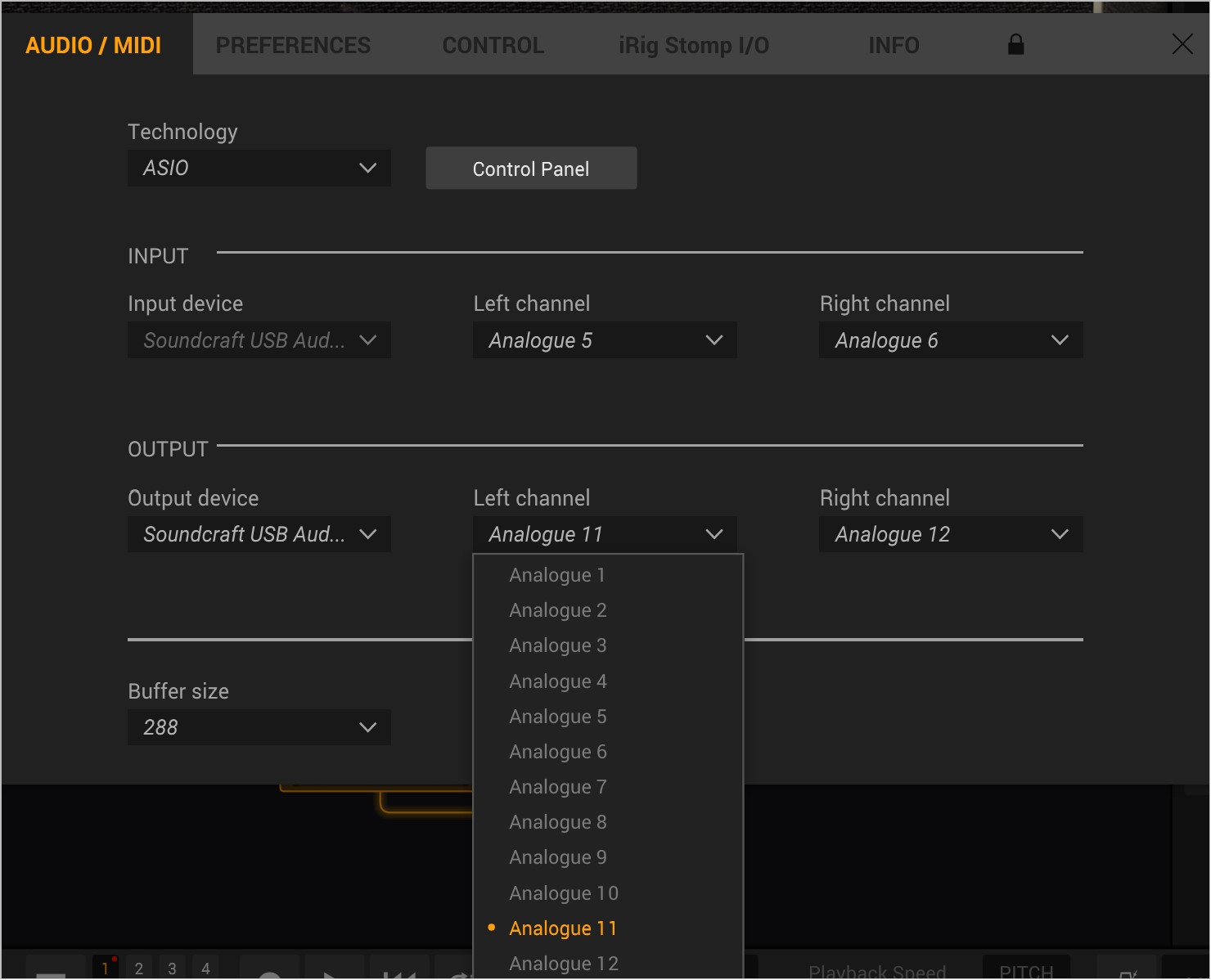
On the not so fun side, Amplitbue 5 was released, but the ASIO support on Windows continues to be a major problem. So I posted here to share my issue
IK Multimedia • Windows 10 Native ASIO Multichannel Driver -NO ASIO4ALL
Am hoping this will become a useful source of information on a longstanding issue.
Please – only info about Windows 10 and native (hardware manufacturer supplied) ASIO drivers. ASIO4ALL is not an acceptable solution.
I am running
Windows 10 build19042.685 64bit
Surface Book 3, i7
Soundcraft Signature 12 MTK Mixer/USB Interface 12 track
-input 14 channels x 24bit
Setup:
INPUTS: Guitar and Bass use the HiZ inputs on the Signature 12 (channels 5 & 6)
OUTPUTS: Output is sent to channels 11 & 12
MONITORING: Main Out and Headphone out from Signature 12 – not on computer
Other software that operates without any issue using this setup
Software that DOES NOT work
Issues:
When I have mucked about – using Channel 1 as input, I did get input showing and the output meters were going too…. but no audible output. even if I tried other channels.
I am really hoping to get a real answer here – and some real understanding on what the IK Team is going to do about this… This was some pricy kit and … as you say… Musicians First, please.
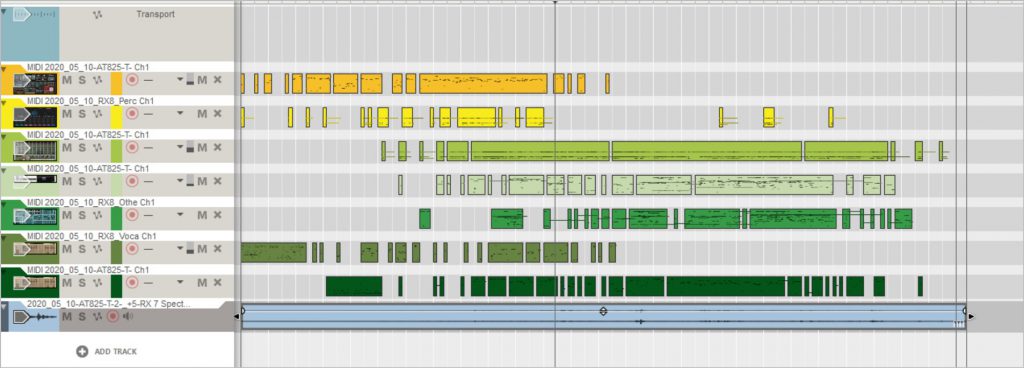
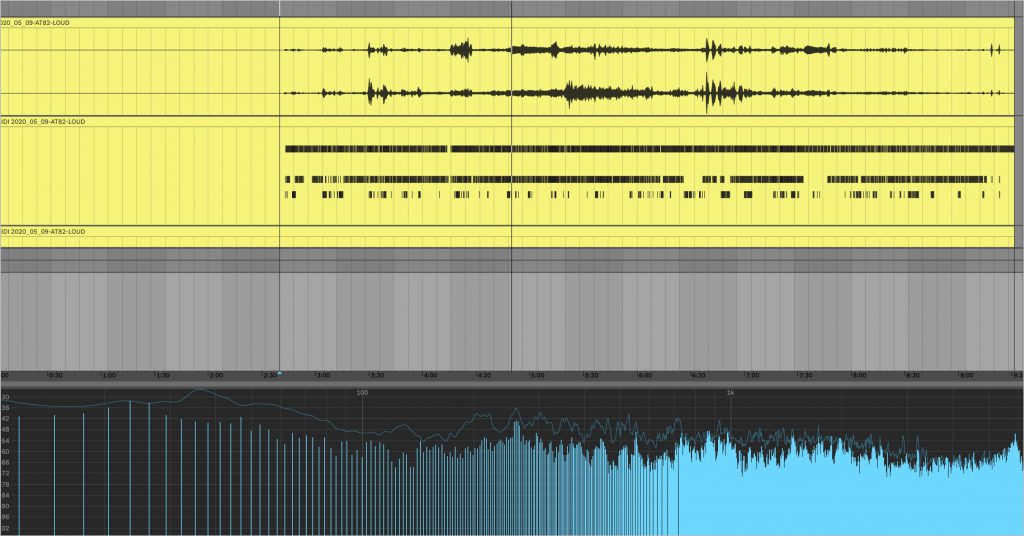
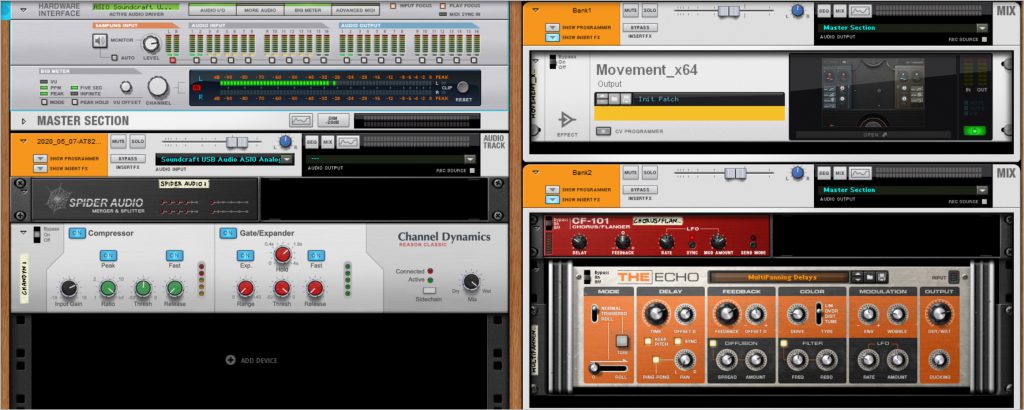
Todays recording could be be called “What the Machines Heard” when you look at the process. From the raw recording I had two tracks of production.
Process and Tech
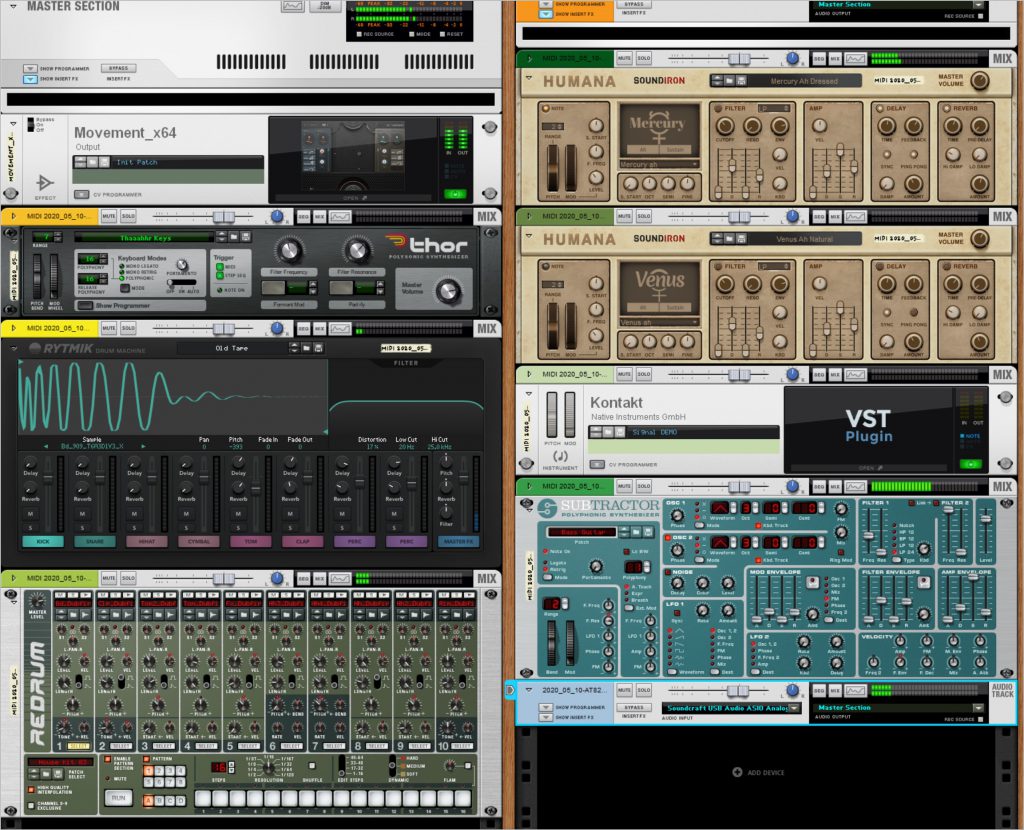
– Process One: Raw recording is then sent through RX8 Music Rebalance which attempts to take an audio stream and tried to identify and isolate, Vocals, Bass, Precussion, and Other and then outputs audio files for each of the components. This is where we can talk about What the Machines hears – and also consider the question of Bias that is implicit in AI/Machine Learning algorithms. That is, the creators of the algo assume that music is made up of voice, bass, drums and other… When that tool is applied to a situation that is not like traditional western popular music, very strange results come out.
– Process Two: Using Ableton Live 10, I loaded the component audio files as well as the raw recording. Then using the Convert to Midi Process – with the outcome being 6 different MIDI files that represent the Harmony, Melody and Drums from the Raw Track. For each of the component files I processed it with a relevant Audio to MIDI process – -so Percussion -> Convert Drums to MIDI, Voice -> Convert Melody to MIDI, Other->Convert Harmony to MIDI, finally Bass was processed as melody.
– With all that, I applied the Midi tracks to relevant synths and then added the raw audio in as a bed. All signals were then sent to the Master bus where Movement was applied with a 50/50 Wet/Dry to give it a bit of a groove. This was all assembled and rendered in Reason 11
I think the results show that there are many, many avenues to follow. This took a long time to pull off because the new opportunities kept presenting themselves. But in a nod to getting the work done and putting it out there, I have not spent time really tweaking the synth sounds. So this – and any other recordings done in this process – offer a very interesting place to experiment with fine tuning the synths.
I also like the synthy “voices” which to me feel like what the aliens would be hearing as the way we speak/sing. And you can hear some of the real voices creeping through the mix.
The News of the day from one of the local New York City papers
https://www.nytimes.com/search?dropmab=false&endDate=20200510&query=05%2F10%2F2020&sort=best&startDate=20200510


This recording was very different than the one yesterday. The levels were very balanced, though a bit low – it was also a much gentler evening. Completely different attitude from the day before. This change gave me the impetus to add a new processing method to the mix Method G is here (i am not sure where Method F is… I’m sure it will turn up… oh yeah that was the attempt to use Reasons Bounce to MIDI function).
The thing about Method G is that is different from all those before it is that it involves analyzing the audio file, and then software creates MIDI scores for Drum, Melody and Harmony. Now feeding in a lot of random sound, with no set, key, meter, tempo – well that puts a lot of trust into the ALGORITHM (algo for short) to figure it out. As you might expect its pretty glitchy, but it is also very valuable.
Think of it this way – you are an alien and you land on this planet and you whip out your tricorder maybe your… TRICHORDER – it samples the environment and does its best to present you with a representation that will bring the phenomena of this planet into a representation that makes sense to your alien cognition. Maybe it makes up for sensing capabilities you don’t have – like X-Ray or FMRI
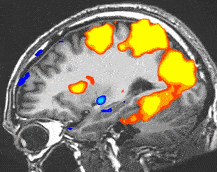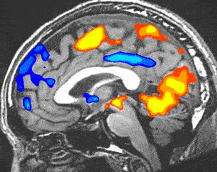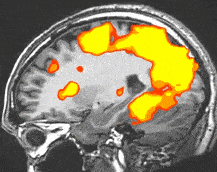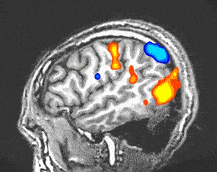
Now think about yourself, encountering a new situation. You don’t have a first hand understanding of the situation, but you want to really understand and get involved. So, you put everything at your disposal to work – you translate text – you do image recognition – you analyze the language that might be spoken (is that a language, or just the sound of living?”
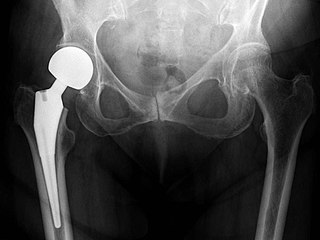
At the end of the day, with all the technology but no person to person interaction you are likely to have a very blurry and confused understanding of the situation. What ever decisions you make to benefit the folks in this situation will be based on biased and inaccurate data. You could very quickly cause a disaster. On the other hand, your sensors could pick up something like there are people with congenital hip dysplasia who could be helped with a well understood operation. You can see, what they cannot.
How to we bring these different views and interpretations of the same situation together? My hypothesis is that you have to just keep trying new “lenses”, adjusting the “parameters” and making observation in a very diverse set of conditions….. and then what??? How can you share that? How can you bring that interpretation, its methodology and data and aggregate it with the interpretation, its methodology and data that someone else has?
This is the Knowledge Building issue of our time. Solving this will have the deepest impact on humanities ability to communicate and forge mutual understanding.
OK – so when I listened to this recording and was struck by the more mellow attitude, and there seemed to be some improvement in the overall recording, it was time to try a different approach. Originally I was thinking about something what would be a sort of shimmering fog over everything. So, I tried out a bunch of things rather blindly after about 3 hours, I decided to do something I rarely do – go back and read some notes that I had taken. In there was mention of another Output plugin I had not tried, but was a constant presence in my Instagram feed. Signal is what Output calls a Pulse Engine.. so why not try that out – there is a demo version I used today.
The first thing I realized was that this was not an audio effect, like Movement and the others, this was a MIDI Instrument. So…. I needed to somehow get a MIDI representation of the audio file (WAV, 48,000, 24bit). Reason has a feature “Bounce to MIDI” but this seemed to only give me the everything on a single note. This could not be the state of the art! Well, I did some research and came upon a piece of software from WidiSoft and I gave their demo a whirl. Once I understood the role and usage of the various algos included, I found that I could generate Drum, Melody and Harmony parts. But, I had the demo version – so I needed to investigate further (mostly I wanted to make sure I didn’t already have what I needed – could Scaler2 or Decoda work – they might, but I got a quick easy answer with Ableton Live 10 which has the functionality built in – no fine tuning that I could see – but it worked.
So now I was ready – I created 3 MIDI channels and put an instance of Signal on each. Then I piped the Drum Midi to one, Melody to the second and Harmony to #3. I also had the raw audio going to Master as were the MIDI tracks. It was really very interesting and fun to interact with in finding the setting I ultimately chose. I then just let it play. After V1 was done I wanted to try putting Movement into the Master channel and have every thing go through it. I left the settings to pretty dry so as not to overwhelm. I think the result is pretty good and there is a whole new universe to sounds and technique open to me. It was a good day.
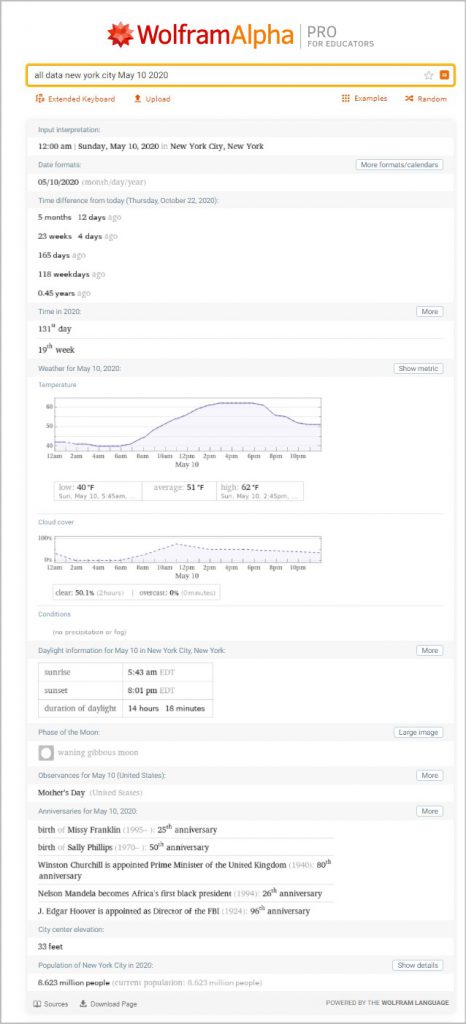
All NYC Data on this day from WolframAlpha:
https://www.wolframalpha.com/input/?i=all+data+new+york+city+May+9+2020
Weather on this day from WeatherUnderground

https://www.wunderground.com/history/daily/us/ny/new-york-city/KLGA/date/2020-5-9
The News of the day from one of the local New York City papers
https://www.nytimes.com/search?dropmab=false&endDate=20200507&query=05%2F07%2F2020&sort=best&startDate=20200509
Time has come to just put out what I have for May 8th. While not satisfied at this point, my intention remains to treat this day’s recording with great care because it is one of the first where a new behavior emerged. This new behavior, having someone in the community actually singing and playing guitar, really challenged the processing approach I had been using. I wanted to share some of the reality of the day – the raindrops in the very beginning of the take, my friend and neighbor Daniel Levy‘s impromptu performance of The Beatles Here Comes the Sun. At the same time a technical glitch caused the gain on the microphone to be set too low for the first couple of minutes – and then with the correction the volume really jumps. Also, the community at large was really raucous that day. You can hear them all jump in at 7pm – Daniel had started a bit earlier.
Juggling all these issues, I lost sight of the process I had originally intended which was to move quickly with a first pass through all the recordings and then go back to ones that were particularly interesting and refine them. Instead, I got sucked into a loop of trial and error with no specific goal. Furthermore, I fell into the trap of downloading a whole crop of new plugins, searching for a silver bullet to both my dynamics problem as well as the over all tone of the piece. Rather than keeping it simple and forging ahead, I wasted about 12 days in this vortex – lesson learned.
But on the positive side – this was an exceptional day. Daniel’s performance in the drizzle – coupled with his spot on song selection – along with the raucous and enthusiastic participation of the crowd. It was a day that really had an emotional impact. I hope this early version is done well enough for some of that to come through.
Technical:
Expect that this day will eventually be revisited when my skills and insights have been sharpened. Below is the unprocessed waveform of the file 2020_05_08-2020_05_08-AT825-T-2-_+5-RX 7 Spectral De-noise. The change in dynamics is pretty evident.

How the raw files are initially processed:
This makes me think I should give a bit more insight into the recording and processing process. The recordings were done live (um… that’s obvious, yeah?) using the microphone in the filename – in this case it is the AT825 which, incidentally, I had borrowed from Daniel Levy a few years ago. Then during the month of July I began reviewing the raw files. This is just after my remote recording rig failed – more on that later. One thing that was clear, all the raw recordings had a lot of wind noise. To clean up the recordings, I was fortunate enough to have a demo version of iZotope’s RX7 (now RX8). In the filename you will find “RX 7 Spectral De-noise” because that was the processing I used. Each recording was individually analyzed and the results were outstanding. It took a couple of days to do, but it was worth it. The resulting files were now ready for action.
May 8 processing – Process E
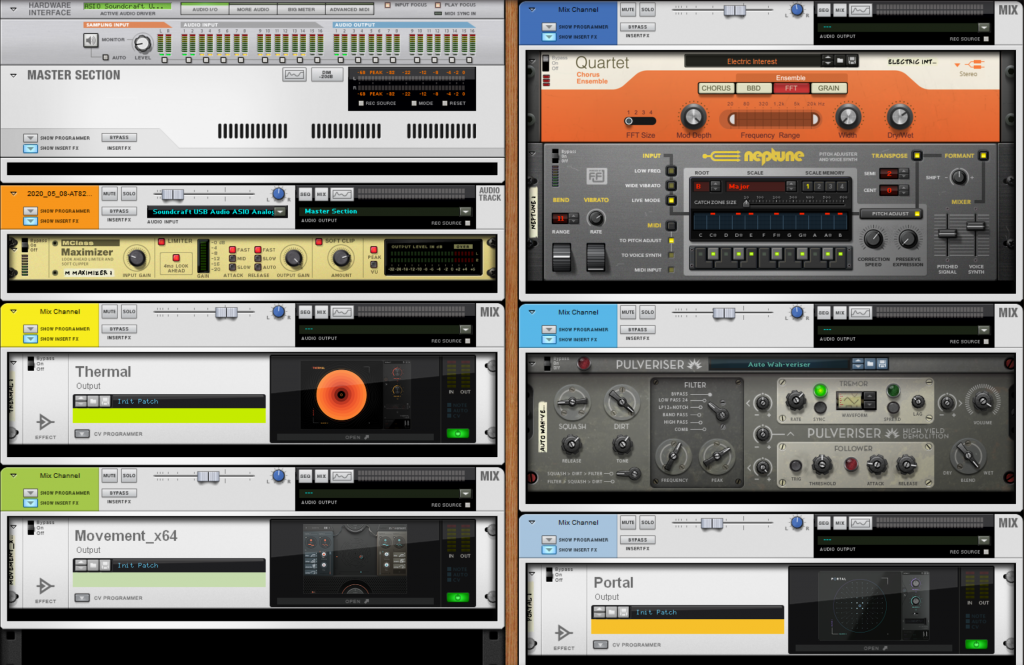
As mentioned ad nauseum, this was a tricky one. The initial work was done to try and boost the gain on the beginning and bring it down when it was very hi. In the end, I put a limiter in there and managed the gain level from there live when recording the track. At this point I was still using Process D which I had used on the 7th, but it seemed all wrong. I stripped everything back and went silver bullet shopping. A few very frustrating days ensued. Finally I decided to step back to what I had felt was my initial success – using Output‘s Movement plugin. Why not see what else they had to offer. So, I decided to try out Thermal and Portal and there was plenty to work with there. I had 5 effects loops total, the other two were using the stock Reason 11 effects. During the recording of the track, I was managing the 5 Effect Sends and the Limiters Input gain. So, this is the first track where I am doing some sort of “performing” during the recording of the processed track.

Weather from Weather Underground – https://www.wunderground.com/history/daily/us/ny/new-york-city/KLGA/date/2020-5-8

All NYC Data on this day from WolframAlpha:
https://www.wolframalpha.com/input/?i=all+data+new+york+city+May+8+2020
It was the 50th anniversary of The Beatles Let It Be album – see below.
From the NY Times that day: https://www.nytimes.com/search?dropmab=false&endDate=20200508&query=05%2F08%2F2020§ions=Health%7Cnyt%3A%2F%2Fsection%2F9f943015-a899-5505-8730-6d30ed861520&sort=best&startDate=20200508
Context Capture Sketching
As mentioned in the project introduction, this project is related to another one – currently called Context Capture. As I move through the 7pm project specifically, though I have had a feeling/frustration/pain for my whole life, the unbelievable difficulty in making statements or expressing ideas in a manner that effectively captures the universe of experiences and influences that shaped that idea or statement. That, if someone doesn’t understand all (or at least a good chunk) of what underlies and informs what I say/play/draw/write/share, they can’t really understand it – that they are only getting a superficial understanding.
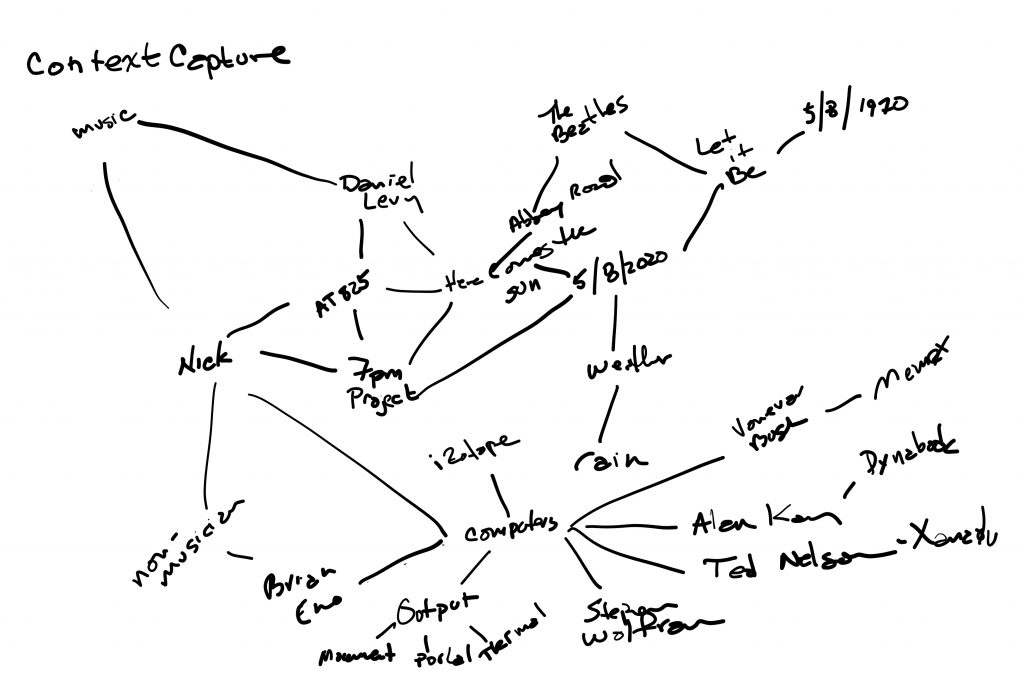
As I write this, it is clear that communication amongst humans, in the age of global information with free distribution, is making it harder and harder to be understood at a time when being able to understand, or at least get a sense of, someone’s life experience has become more and more important – imperative really. For me there are those who have blazed this trail – many years ago – and they are largely forgotten by the current digital elites and the people deciding what ideas have “value” and are worth “investment”. I look back, always, to Vanevar Bush and his Memex, “Ted” Nelson and his Xanadu, Claude Shannon and Information Theory to Alan Kay and his DynaBook as the ones who have plotted the course, we need a new generation to heed the call and work for a new mode or medium of communication that is much richer and simply conveys ones context along with the immediate message. This is also critical for the true formulation of knowledge on an individual and collaborative nature. More on this later. But here is a sketch of part of the knowledge graph that makes up this post — I only spend 2 minutes on it – its missing a lot.
Nothing like realizing that you really should be running your site with HTTPS and then spending hours digging through the gnarl to get it set up. And it costs ya money. But even with the frustrations (mostly self-induced) I was impressed at how much easier it is to deal with than back in the olden times.
Surf safely
Project Theory and Development:
Today – in real time – that is September 23, 2020 there was a piece on NPR about a new movie – The Secrets We Keep – staring Naomi Rapace. In the interview, she gives a brief plot synopsis that mentions that the plot revolves around her character hearing a specific whistle – one that she instantly recognizes from her past. This is exactly the sort of thing I was thinking about when structuring this project – the calls of the community member – that you could know them without seeing them – that the calls are personal and unique.
Technical Stuff:
On this day, I decided to switch microphones from the AT2035 Large Condenser to the AT825 which is a Stereo Mic more suited to field recordings. The results were much better – better rejection of the in-house sound and better pickup of the community. Also, the crowd was much more active
All NYC Data on this day from WolframAlpha:
https://www.wolframalpha.com/input/?i=all+data+new+york+city+May+7+2020
Weather on this day from WeatherUnderground
| 6:51 PM | 66 F | 20 F | 17 % | W | 16 mph | 25 mph | 29.69 in | 0.0 in | Mostly Cloudy |
| 7:51 PM | 64 F | 21 F | 19 % | SW | 14 mph | 23 mph | 29.71 in | 0.0 in | Partly Cloudy |
The News of the day from one of the local New York City papers
https://www.nytimes.com/search?dropmab=false&endDate=20200507&query=05%2F07%2F2020&sort=best&startDate=20200507
